|
Hi! I am a first-year master at Tsinghua University, majoring in Data Science and Information Technology (DSIT). I expect to graduate in 2028. I am fortunate to be supervised by Prof. Yansong Tang in IVG@SZ group. Previously, I received my B.S. degree in Computer Science and Technology from Sichuan University in 2025. My research interests lie in Multimodal Large Language Models (MLLMs), Reinforcement Learning, and Video Reasoning. Google Scholar / Email / Github / LinkedIn |

|
|
|
|
|
|
|
|
|
|
|
(*Equal Contribution, †Corresponding Author) |
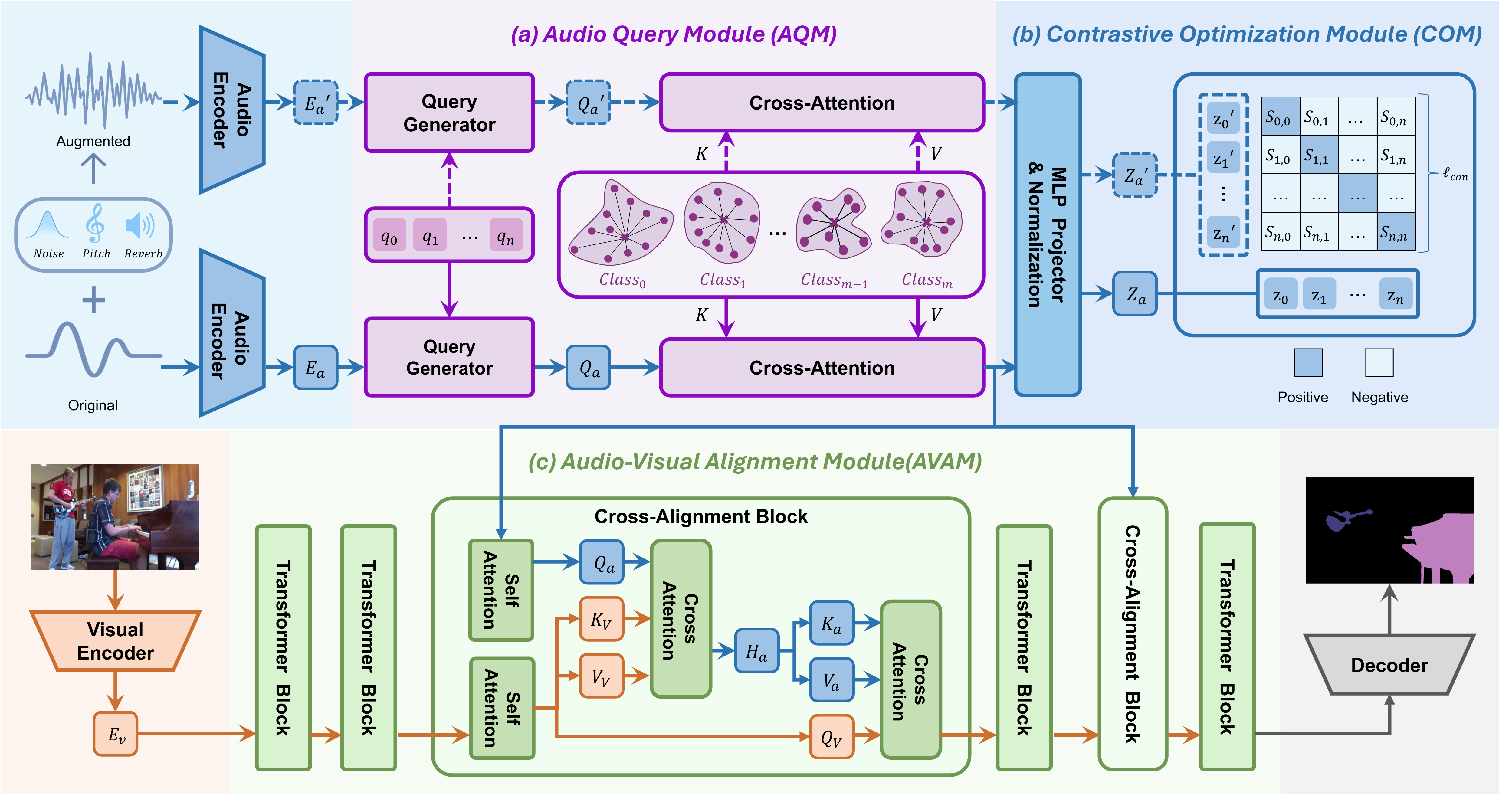
|
Jingqi Tian, Yiheng Du, Haoji Zhang, Yuji Wang, Isaac Ning Lee, Xulong Bai, Tianrui Zhu, Jingxuan Niu, Yansong Tang† European Conference on Computer Vision (ECCV), 2026 [arXiv] [Paper] [Project Page] We propose DDAVS, a disentangled audio semantics and delayed bidirectional alignment framework for audio-visual segmentation. |
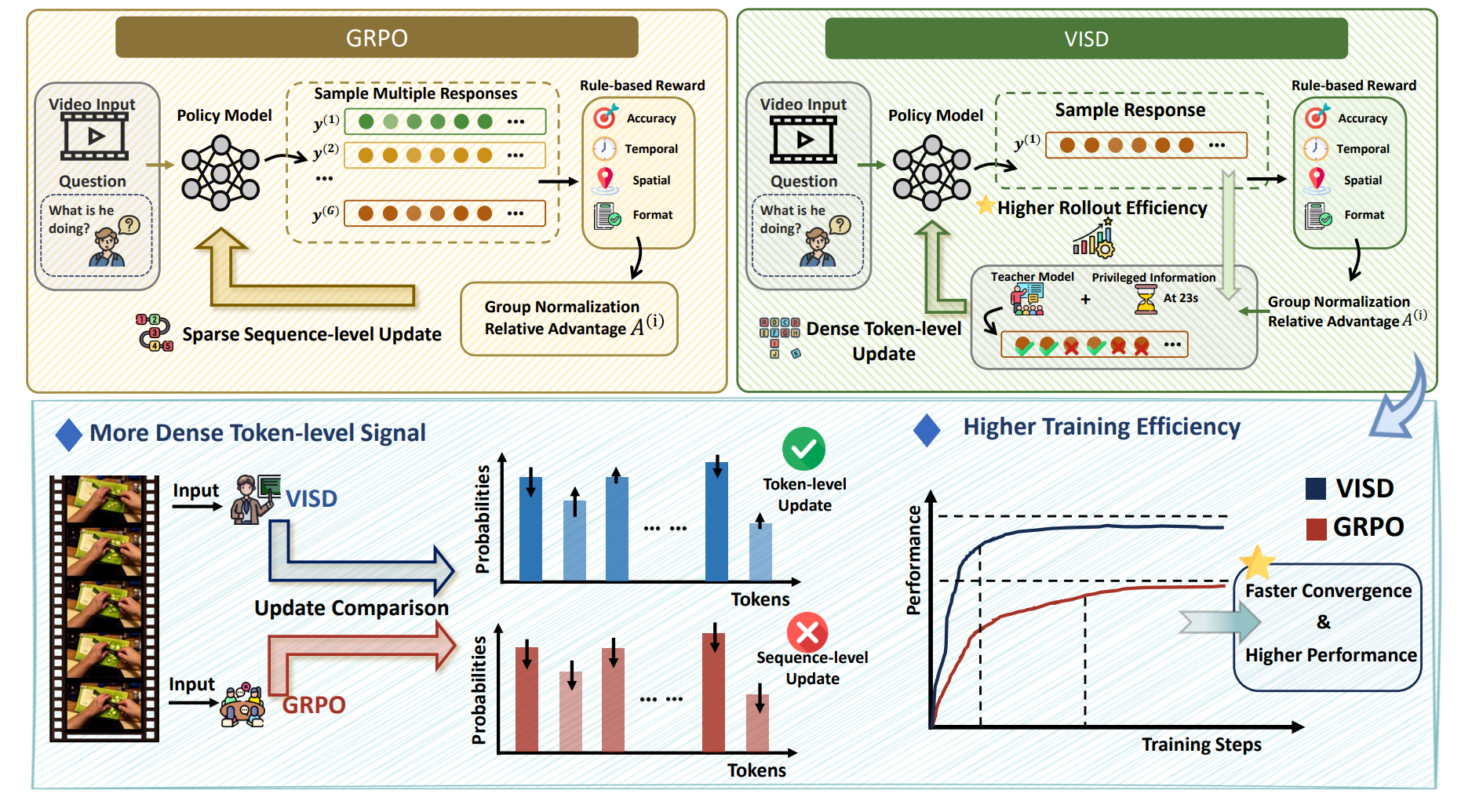
|
Hao Lin*, Kunyang Lv*, Xu Jiang, Jingqi Tian, Zhongjing Du, Jiayu Ding, Qiaoman Zhang, Hongbo Jin† Preprint, 2026 [arXiv] [Paper] [Code] [Project Page] We propose VISD, a structured self-distillation framework for enhancing video reasoning. |
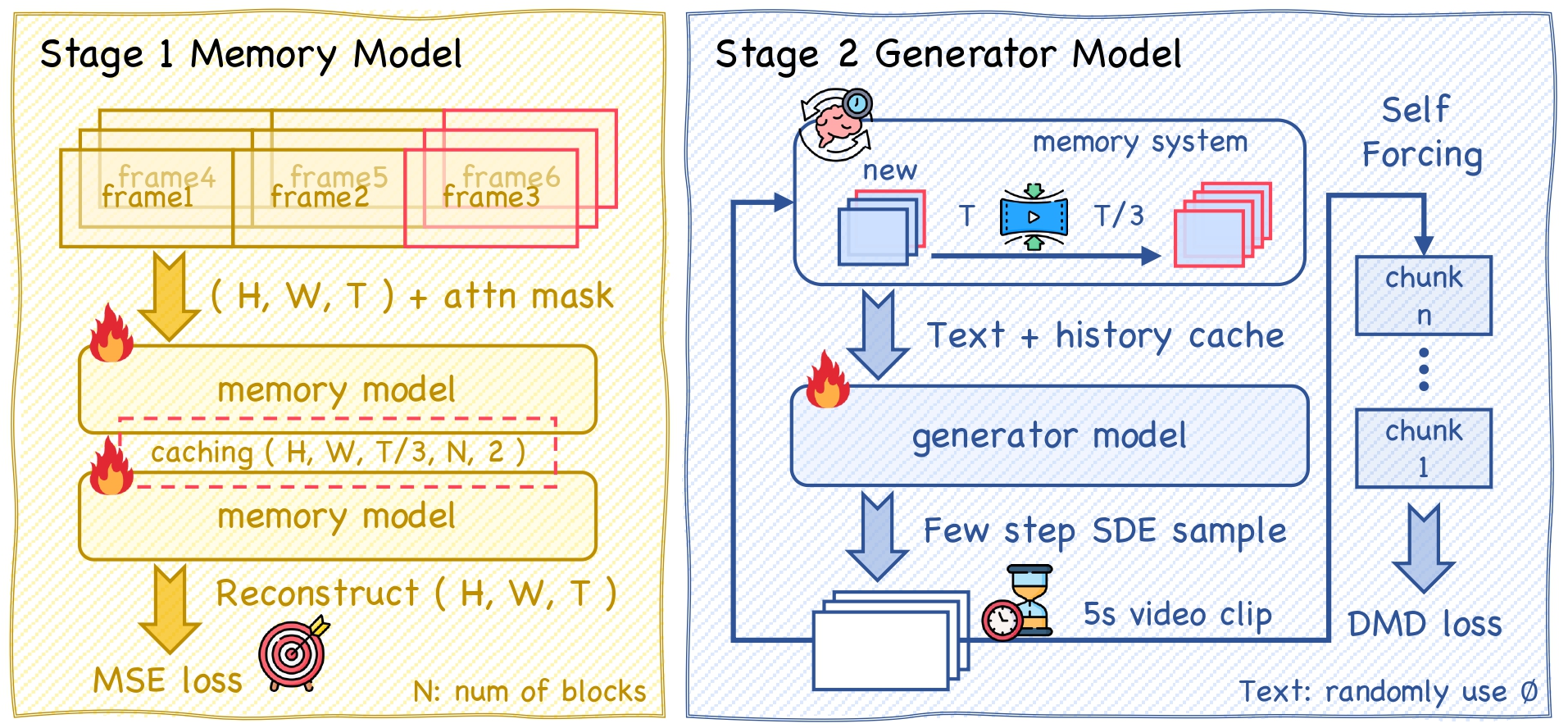
|
Tianrui Zhu*, Shiyi Zhang*, Jingqi Tian, Zhirui Sun, Yansong Tang† Preprint, 2025 [arXiv] [Paper] [Code] We explore MAG framework, which decouples memory and generation into independent tasks, aiming to enhance historical scene consistency while achieving efficient compression for GPU memory. |
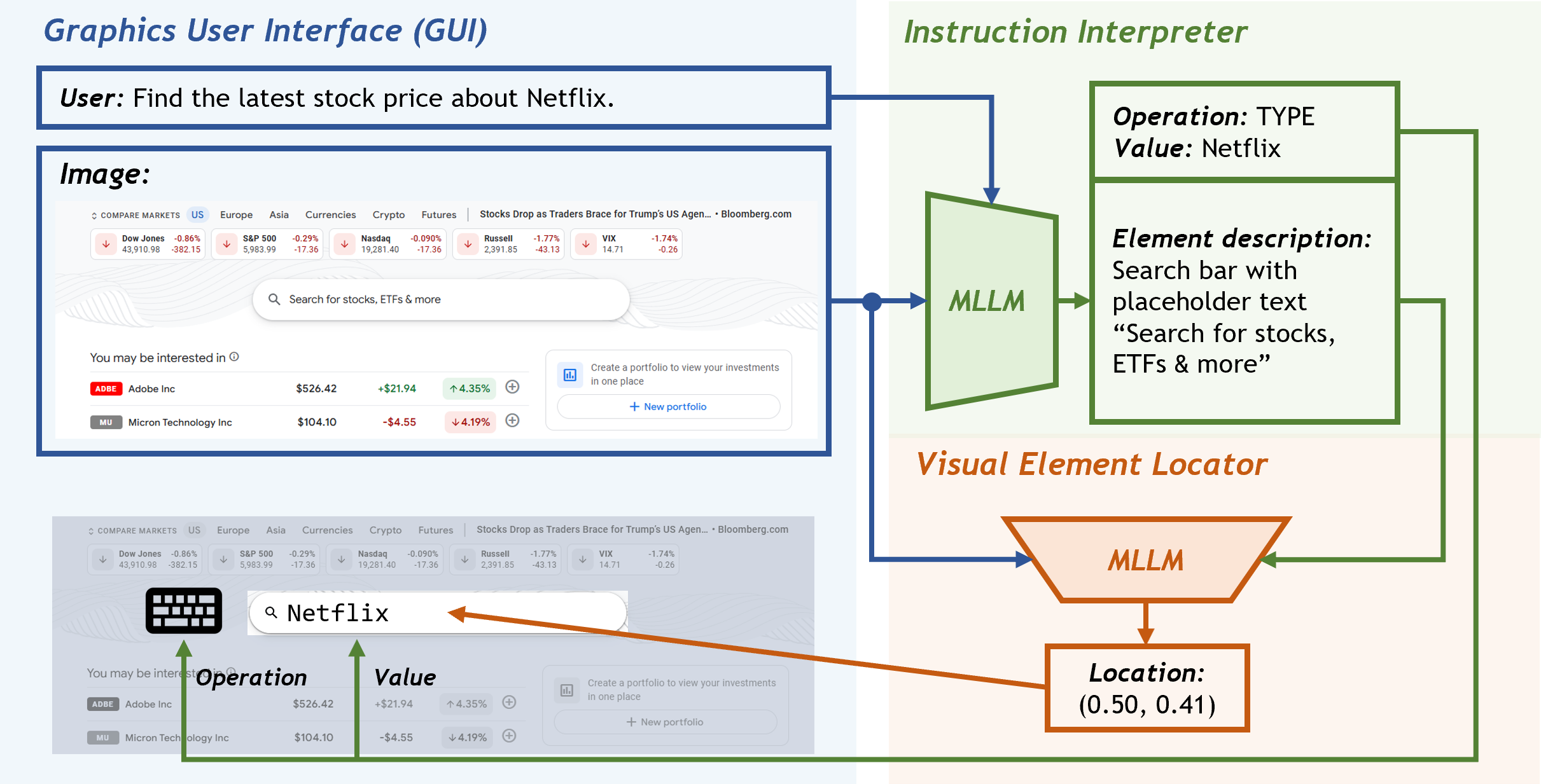
|
Yiqin Wang*, Haoji Zhang*, Jingqi Tian, Yansong Tang† Findings of the Association for Computational Linguistics (ACL), 2025 [arXiv] [Paper] [Code] [Project Page] We propose Ponder & Press, a divide-and-conquer GUI agent framework that only relies on visual input to mimic human-like interaction with GUIs. |
|
|

|
|

|
|
|
|
|
|
